A könyvben – a magyar cím: Jogiontológia-tervezés – annyi a filozófia, mint egy barkácsáruház termékkatalógusában. Igazság szerint körülbelül a funkciója is ugyanaz. Ha valaki ontológiatervezésre adja a fejét, akkor ebben a kötetben megtalálhatja mindazokat az eszközöket, amelyekre szüksége lesz a tervezés és az építés során. Ez a tevékenység (az ontológiatervezés) mérnöki munka. Többnyire mérnökök (mérnökszerű szakemberek) végzik bevonva mások közt jogi szakértőket. Essünk túl a rossz híreken: a szóban forgó katalógus lejárt.
A könyv katalógusjellegéből fakadóan nem igen ad lehetőséget jól vagy rosszul sikerült érvek bemutatására. Amiért talán mégiscsak helye lehet a Kiskáté rovatban a róla szóló írásnak – a szerkesztők jóindulatán túl –, az az, hogy a szóban forgó szakemberek impertinens módon, szemrebbenés nélkül használják az „ontológia” terminust. Azonban ez talán sekélyes indoklás, hiszen az efféle transzdiszciplináris fogalomvándorlások nem szokatlanok a tudománytörténetben.
Gyorsan áruljuk el, hogy mit is jelent az „ontológia” kifejezés a könyv címében, hogy ne legyen zavaró a homonímia (zavarjon helyette más)! Mit csinál az, aki (jogi) ontológiát tervez (épít)? Többnyire számítógépes eszközökkel megpróbálja leírni és összefoglalni egy adott terület fogalmait és ismereteit. Ezzel éppenséggel sokan lehetnek így, ettől még az eredmény nem feltétlenül ontológia. Az ontológia a tudásreprezentáció egyik eszköze, amelyben az összegyűjtött terminusok összefüggéseit viszonylag formalizálva adjuk meg. A tudásreprezentáció és a viszonylag formalizálva azért pontosításra szorul. Bármit sugalljon is a „tudásreprezentáció” szó, ebben az esetben valamiféle informatikai keretről van szó. A viszonylag formalizálva kifejezést pedig talán a következő ábra segít megérteni a kötet 22. oldaláról (a szerző Ora Lassila és Deborah McGuinness 2001-es tanulmányából kölcsönzi).
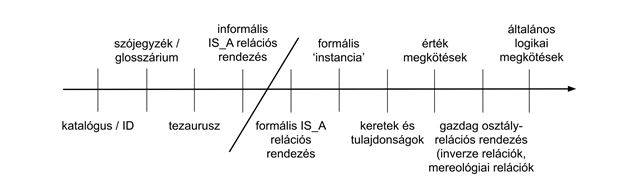
Anélkül, hogy az ábra részleteit elemeznénk, jól látszik: ha terminusokat akarunk számba venni, akkor nagyon sok mindent csinálhatunk. Például felsorolhatjuk őket, a felsorolt szavakat rendezhetjük, különböző szabályokat fogalmazhatunk meg a szemantikájukra vagy más tulajdonságaikra vonatkozóan, formális kikötéseket tehetünk a rendezésekkel kapcsolatban, stb. A nyíl az ábrán a rendezésre használt eszköztár gazdagságát jelöli: az egyszerű enumeratív felsorolástól a nagy apparátust megmozgató vállalkozások felé mutat. A ferde vonal bal oldalán olyasmiket találhatunk, mint az alfabetikus rendezések, a szógyakoriság-szótárak (lásd például a Beke József szerkesztésében megjelent Radnóti-szótárt [Argumentum Kiadó, Budapest, 2009] és Büky László kritikáját a Magyar Nyelvben) vagy a tezauruszok (informális fogalmi rendezések; például az Ungváry Rudolf főszerkesztésében összeállított OSZK Tezaurusz). A fogalmak rendezésének feszesebb formáját jelenti, amikor hierarchikusan (osztály) rendezzük a fogalmakat, és formális relációkkal (például mereológiai relációkkal: része stb.) és materiális relációkkal (gyámja) rendeljük őket egymáshoz. Az ábrából kiderül, hogy körülbelül (ferde vonal) hol kezdődik az, amit ontológiának nevezünk. Mereológiai relációk, osztályrendezés (is_A), tulajdonsága-relációk (has_A) – ezek tényleg nagyon hasonlítanak ahhoz, amit szokásosan ontológiának hívunk a filozófiában: milyen absztrakciós szinten tudjuk elmondani, hogy mi van.
A szerző, Núria Casellas jogi informatikával foglalkozik; ez a könyv a doktori kutatásának és a részvételével zajló tudományos projektnek (Iuriservice) az eredményeit foglalja össze. A kötet átfogóan bemutatja a mesterséges intelligencia és a digitalizáció megjelenésével az 1980-as években megindult számítógépes jogi szakértői rendszerek kidolgozásának első két szakaszát. Az azóta eltelt időszakban a jogi informatika önállósodott, fontos kutatási területté vált, amelyen – a korai holland hegemónia után – nagyon sok különböző kutatóműhely jelent meg; folyóiratokban, kompetitív nemzetközi konferenciában, tanszékekben intézményesült.
A könyv széles áttekintést ad a jogiontológia-építés első három évtizedéről, és bemutatja, meddig jutottak el a szakemberek a 2010-és évek elejéig: milyen eszközökkel miféle konceptualizációk mentén milyen alkalmazásoknál tartottunk akkor. Bár a könyv fókusza a jogiontológia-építés, az első fejezetek távolabb tekintenek, és a laikus olvasóknak is értelmezhető és használható betekintést nyújtanak az ontológiai típusú tudásreprezentációk működésébe. A „laikus” itt azt a jogi szakértőt jelenti, akinek van nyitottsága a technológia iránt. Ez azért is fontos, mert ahogy Casellas többször is utal rá a könyvben, a jogiontológia-építésnek az az egyik sajátossága, hogy nem jogászok csinálják. Vagy másként: a jogi dogmatikai tudást az ontológiaépítési gyakorlat még kevéssé tudja operacionalizálni. Persze ez általában véve is igaz: a technológiai innováció a technológiához értők kezében van, tehát ami progresszív a társadalomtudományok területén, azt nem feltétlenül társadalomtudósok (bölcsészek, jogászok) csinálják. Ahol van nyitottság a tervezői (mérnöki) és a társadalomtudományi oldalról, ott is kiderül, hogy milyen nehéz a közeledés – a mérnök nem azzal van elfoglalva, amit a társadalomtudós problémaként ismer fel, viszont sokkal mélyebb (vagy másképpen mély) a tudása például az algoritmusokról, mint ahogyan azt a társadalomtudós feltételezi. Nehéz a párbeszéd; de nem nagyon lehet megúszni, hogy alaposan megértsük a technológiát.
A könyv első fejezetei tehát szélesebb áttekintést nyújtanak, és nem csupán a jogiontológia-építésről szólnak. Ugyanis nagyon sokan, és nagyon sokféle megfontolással építenek ontológiát: a webshop-architektúra készítőitől kezdve a biomedikai vagy a hírszerzési szakértői rendszerek építőiig. A tervezés módszerei többé-kevésbé közös elemekből állnak: specifikáció, ismeretszerzés, konceptualizálás, formalizálás, értékelés, finomhangolás; a különbségek lényegében abban állnak, hogy ezek a projektek milyen minőségbiztosítási szűrőket használnak, hiszen a nagyszabású vállalkozásoknál szükség van projektellenőrzési pontokra. (Lásd: Ushold and Grüninger 1996; CommonKADS; METHONTOLOGY; OD 101; OTK; DOGMA; 47-step guide; UPON.) Léteznek különböző, a formalizáláshoz szükséges leíró nyelvek, és léteznek olyan eszközök, amelyek a formalizálást segítik: például szerkesztők vagy a természetes nyelvi input szöveg feldolgozását támogató annotáló eszközök. (Lásd a 2000-res évek legnépszerűbb ontológiaszerkesztő környezeteit: Alceste; AntConc; GATE; ONtoGen; OntoLearn; indexOntoLT; Terminae; TextOntoEx; Text2Knowledge; Text2Onto; Yoshikoder.) A formális leíráshoz fejlesztettek implementációs nyelveket (KIF, Ontolingua, FLogic, Loom stb.), később webes leíró nyelveket adaptáltak ontológiaépítéshez (SHOE, XML, XOL, RDF, RDFS, SKOS, DAML+OIL, OWL; kifejezetten jogi szövegek strukturális és a szövegben lévő fogalmak relációinak leírására a LegalRuleML leíró nyelvet használják [RAWE LegalRuleML editor]). A leíró nyelveket speciális fejlesztőkörnyezetekben lehet használni (DOGMAModeler, DOGMA Studio Workbench, DOODLE-OWL, KAON2 & OLW Tools, NoON Toolkit, Ontolingua & Chimaera, Protégé, WebODE). A szemantikus webes standardok nagy változást hoztak, részben mert fontos cél lett a weben elérhető tartalmak feldolgozása, részben mert nagyon erős szabványok (XML, RDF, OWL) készültek hozzá.
Amikor elkezdődik valami, először különféle ötletek és megoldások jelennek meg az intellektuális piacon, majd a versengő ajánlatok közül – nyilván sok tényező függvényeként – némelyik győzelmet arat. A szemantikus webbel is pontosan ez történt. A szemantikus web fogalma azt a technológiát takarja, amelynek révén – gépi segítséggel – olvashatóvá válik a webre került karaktersorozatok tartalma. Ehhez arra van szükség, hogy valamilyen módon számot tudjunk adni a weboldalakon található szövegek tartalmáról. Mit jelent ez? Vegyünk megint egy könyvtáros példát: egy könyv adatait a katalogizálás során különbözőképpen rögzíthetjük, például leírhatjuk a fizikai adatait vagy összegyűjthetjük az eredetre vonatkozó információkat, amelyek segítségével rendezhetjük és visszakereshetővé tehetjük a nagy adatkönyvállományt. Az ETO-hoz (Egyetemes Tizedes Osztályozás, nemzetközi egyetemi osztályozórendszer) tartozó osztályozások már mélyebb, tartalmi betekintést (és rendezhetőséget) adnak a könyveknek. A könyvtárban ülő Balassi-szakértő tudása e felfogás szerint nem más, mint a könyvek (egy részének) nagyon mély leírásának ismerete. A szemantikus web a webes tartalmak leírásának ilyen elmélyítését teszik lehetővé azzal, hogy egységesítik a leíró szabványokat. A standardizálásért felelős W3 konzorcium az ontológiai leírás formális kereteit és nyelveit is standardizálta. Többi ilyen nyelv is létezik; és Casellas könyvének megszületésekor még sokkal nagyobb verseny volt a piacon, mint manapság, amikorra az OWL-nyelvcsalád (ontology web language) vált a bevett ontológiai leíró nyelvvé.
A terminusrendezéshez különböző komplexitású relációs struktúrákat használhatunk. Ez a terminusrendezés kifejezés azért egy kicsit elkendőzi, hogy valójában nagyon éles (fogalmi tisztázó) viták zajlottak róla, mit is „rendez el” az ontológia valójában. „A filozófiában úgy beszélünk az ontológiáról, mint szisztematikus számvetésről mindazzal, ami van. Az emberi tudást felhasználó mesterségesintelligencia-rendszerekben az ontológia nem más, mint ezt a tudást leíró (reprezentáló) formális terminusstruktúra, amely teljes mértékben megadja a rendszer számára, hogy mi »létezik«.” (18. oldal, a szerző Tom Gruber 1992-es tanulmányából idézi.) A javaslatok egy része a reprezentáció rendezettségére (felsőszintű deklarált fogalmi, terminushierarchia) vonatkozik, más része a formájára, a megformáltságára (annak a tudásnak az explikálására, amivel egy „megismerő ágens” rendelkezik), egy másik része pedig a céljára (például tudásreprezentáció előállítása gép és ember számára egyaránt feldolgozható, olvasható formában).
Az, hogy mit is fogadjuk el ebből, részben attól függ, mire is akarjuk használni az ontológiát. Amiből az is következik, hogy legitim döntés különféle ontológiákról beszélni – s ha már többféle van belőle, akkor tipizálni is lehet őket. Lásd a következő két ábrát; a második a kötet 53. oldaláról származik, az első ennek áttekinthetőbb változata.
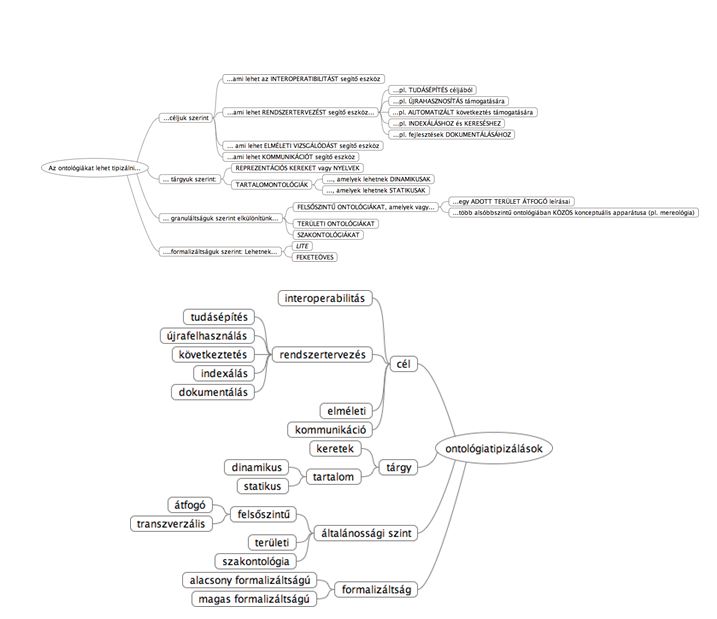
Bár a szerző nem magyarázza el részletesen, az ábra alapján világos: nagyon sokféle céllal készülhetnek ontológiák. Talán a legérdekesebb, amikor az ontológia valamilyen elméleti vizsgálódás reprezentációs vagy kontrolleszköze, de a másik három lehetőség fontosabb: oda kell ontológia, ahol nagy mennyiségű információ számítógépes feldolgozása, kezelése, rendszerezése a feladat. Hasonló ontológiai eszközt használtak korábban a keresőmotorok a lecrawlozott és indexált weblapok tartalmának a „megértéséhez” – annak érdekében, hogy minél relevánsabb eredményt adjanak vissza a keresőkérdésre. (A releváns eredmények megtalálásának másik, ettől független eszköze volt a Page-ranking, amely a weboldalak hipertextualitását használta. Manapság más szemantikus technikákat használnak erre.) Az ontológiaépítés másik fontos célja lehet, hogy segítse valamilyen lezárult projekt eredményeinek újrafelhasználását. Ez különösen életbevágó lehet azokban az esetekben, amikor a jelenlegi informatikai környezet valamilyen okból nem alkalmas két évtizeddel korábbi alkalmazások futtatására. Ugyancsak szükségünk lehet ontológiaépítésre, ha arra törekszünk, hogy gépi segítséggel kibontsuk a szakértői intuíciót kifejező megnyilatkozások implicit, hallgatólagos tartalmait. Az ontológiák – formalizáltságuk fokától függően – alkalmasak lehetnek ilyesféle gépi következtetések levonására. Például a hírszerzésben nagyon sokféle információ (nyílt információ, fedett akcióval szerzett információ) érkezik be, és ezek többféle típushoz tartoznak (szövegek, képek, hangok, térképek stb.). Az adatintegráció – a megbízhatók és a kevéssé megbízhatók, a fontosak és a kevéssé fontosak – gépi támogatásához szükség lehet olyan átfogó (core) ontológiára, amelynek segítségével lehetővé válik az adatok osztályozása és kiértékelése. Végül fontos kiemelni az emberek közötti kommunikációt segítő ontológiákat, amelyek megalkotása során különféle felkészültséggel (és szótárral) rendelkező szakértőknek szóba kell elegyedniük egymással. (Ha például egy filozófus és egy informatikus beszélget egymással, köztük bizony félreértésekre adhat alapot a filozófiai terminológiából a számítógépes információs rendszerekbe importált kifejezések használata.)
Ha ezen a ponton az olvasó elunta a cikket, és/vagy nem akarja folytatni, de nem tudja, mit kezdjen a szabadidejével, akkor ajánlok egy feladatot. Gondolkodjon el azon, hogy miféle dolgok a következők (vagy milyen típusúak, milyen dolgokhoz kapcsolódnak, milyen fogalmakat kell felvenni a rendszerünkbe ahhoz, hogy minél pontosabban megadjuk a jelentésüket): forgalmi dugó, második trimeszterben lévő gravida, rés, büntetés-végrehajtási intézet igazgatója, stoptábla!
Akik nem hagyták abba az olvasást, azoknak azt javaslom, térjünk vissza még egy pillanat erejéig a legutóbbi ábrához! Amikor a világ egy darabjára vonatkozó konceptualizációt szeretnénk explicitté tenni valamiféle ontológia segítségével, akkor a világnak erre a darabjára különböző „felbontásokban” tekinthetünk rá. Ha egészen kis felbontású a rátekintés, akkor felsőszintű ontológiákról (upper-level ontologies) beszélünk; ezek esetében magas absztrakciós szinten adjuk meg, hogy egyáltalában mi van a világban: az entitások dologtípusúak és/vagy eseménytípusúak lehetnek (vö. Eddy M Zemach „Four ontologies” című 1970-es tanulmányával, Journal of Philosophy, 67, 231–247). E dimenzió másik végpontján nagyfelbontású, részletgazdag leírásokat (terminológiát) találunk. Például egy adott tudományterület szakértői által konszenzuálisan elfogadott entitások (mondjuk a sejtek, összetevőik és fiziológiájuk) vagy egy adott intézmény felépítésében szerepet játszó ágensek és alárendeltségi viszonyok, szervezeti felépítés és jogosultsági viszonyok stb. leírását. Ez utóbbiakat szakontológiának vagy domain-ontológiának szokás nevezni. A kettő közötti ontológiákat mezzoontológiának (core ontologies) hívjuk.
Mutatok egy jogi példát! Izgalmas vállalkozás lenne egy adott törvényben használt fogalmakat szisztematikusan ábrázolni. Legyen mondjuk ez a családtámogatási törvény (1998. évi LXXXIV. törvény a családok támogatásáról)! A törvény arról rendelkezik, hogy a magyar állam különböző jogcímeken kinek köteles támogatásokat folyósítani a családok segítése céljából. A törvény szövege nem könnyű olvasmány, és megpróbálhatnánk olyan alkalmazást készíteni, amelynek segítségével bárki könnyen megtudhatja, hogy jogosult-e családtámogatást igénybe venni vagy sem, és ha igen, akkor mennyi pénzt kaphat. A családtámogatási törvény felsorolja, hogy kik azok, akikre egyáltalán vonatkozik a törvény (személyi hatály), kik a jogosultak, és minek alapján azok, továbbá rendelkezik arról, milyen módon történjen a folyósítás. Például a törvény a Magyarország területén élő magyar állampolgárokra hatályos, továbbá mások közt – ez most hosszú lesz – a szabad mozgás és tartózkodás jogával rendelkező személyek beutazásáról és tartózkodásáról szóló törvény (a továbbiakban: Szmtv.) szerint a szabad mozgás és tartózkodás jogával rendelkező személyre, amennyiben az ellátás igénylésének időpontjában az Szmtv.-ben meghatározottak szerint a szabad mozgás és a három hónapot meghaladó tartózkodási jogát Magyarország területén gyakorolja, és a polgárok személyi adatainak és lakcímének nyilvántartásáról szóló törvény szerint bejelentett lakóhellyel rendelkezik.
Ez a szabályrendszer viszonylag könnyen megadható úgy, hogy kikötjük: a személyi hatály azokra terjed ki, akik egyszer rendelkeznek azzal a tulajdonsággal, hogy Magyarország területén élő és magyar állampolgár, illetve – itt most nem idézem újra a törvényt – a harmadik említett tulajdonság is igaz rá. Ahhoz, hogy a jogosultsági applikációnk működjön, nem kell tisztáznunk a „magyar”, az „állampolgár” stb. jelentését. Elég tudnunk (az applikáció felhasználójának tudnia), hogy a kérdéses személy rendelkezik-e az adott tulajdonsággal – és persze további tulajdonságokkal (hány gyermeke van, tanköteles korúak-e a gyermekek, börtönigazgató-e és ebben a minőségében akarja-e a jogosultságát megtudni, stb.). Ha ambiciózusabbak volnának a céljaink, például fogalmi eszközökkel ellenőrizni szeretnénk, hogy valaki tényleg rendelkezhet-e az adott tulajdonsággal, akkor már hosszabb leírást kellene alkotnunk, ami komolyabb munkát igényelne. Például a jog gyakorlása kezdete, a jog gyakorlása stb. fogalmak segítségével fel kell bontanunk az eddig primitívnek tekintett terminust (a szabad mozgás és tartózkodás jogával rendelkező…). Vagy általában véve jó fogalmi leírást kellene adnunk arról, hogy mi a hatályosság. Mivel a hatályosság, a jog gyakorlása stb. nem csak a családtámogatási törvényben fordul elő, ezért fontos lehet egy magasabb absztrakciós szinten jogi mezzoontológiát építeni – méghozzá úgy, hogy a mezzoontológiában tisztázott fogalmakat a családtámogatási törvény mikroontológiájában is használni lehessen. És hasonlóképpen abba a kérdésbe is beleütközhetünk, hogy egyáltalában miféle entitások is a jogosultságok, a társadalmi intézmények, szerepek stb. Ilyenkor kétségbeesetten sóhajtozunk, bárcsak lenne egy jó topontológiánk.
Ráadásul súlyos problémát jelent, hogy a törvények nem magukban állnak. Persze soha nem gondoltuk másképpen, de érdemes tudatosítani: az ontológiai leírás számára ez komoly kihívást támaszt. Például a közlekedési jogszabály rendelkezik arról, hogy a rendőr milyen módon írhat felül karjelzéseivel más előírásokat (jelzőlámpát igen, balra kanyarodni tilalmat nem). De azt nem mondja meg, hogy mi a rendőr, vagy hogy hogyan lehet felismerni az utcán. Persze ez a mindennapokban – néhány extrém kivételtől eltekintve – nem jelent nehézséget, de ahhoz, hogy a szóban forgó részleteket is a reprezentáció részévé tegyük, más, akár alacsonyabb szintű szabályzásokat is fel kell vennünk a rendszerbe (végrehajtási rendeletek, miniszteri utasítások stb.).
Ez az ontológiaépítés – hogy is mondjam? – munkaszervezési dilemmája: felülről lefelé lássunk-e hozzá az építkezésnek, az általánosabb fogalmakkal kezdve, vagy alulról felfelé haladjunk, esetleg középről mindkét irányba terjeszkedve (lásd M. El Ghosh és szerzőtársai 2016-os tanulmányát: „Towards a middle-out approach for building legal domain reference ontology”, International Journal of Knowledge Engineering, 2)? Elméleti válasz helyett talán inkább érdemes a munkaszervezés szempontjára koncentrálni (még ha ez fájóan praktikus szempont is…): mielőtt nekilátnánk a feladatnak, nagyon pontosan tudnunk kell, mit is remélünk az ontológiánktól.
A felsőszintű ontológiák építése valójában nagyon is filozófiai vállalkozás, és filozófusok vesznek részt benne. A legismertebbek közülük a DOLCE és a SUMO, amelyet a jogi ontológiák építése során is használnak (vagy legalábbis utalnak rájuk). Casellas könyvének kiadásakor ugyan már létezett, de ténylegesen csak 2010 után nyert teret a Basic Formal Ontology (lásd Robert Arp, Barry Smith és Andrew D. Spear 2015-ös könyvét: Building ontologies with Basic Formal Ontology, Cambridge, MA, MIT Press), amelyet elsősorban a biomedikai területeken használnak.
Casellas könyvének egyik legfontosabb fejezete („Legal ontologies”, 109–170) azokat a mezzoszintű ontológiákat mutatja be, amelyek a 2010 előtt időszak ontológiai alkalmazásainak alapjai vagy melléktermékei voltak. A szerző elsőként a preontológiákról beszél, vagyis azokról a konceptualizációkról, amelyekre a későbbi ontológiaépítők előzményként tekintenek. Casellas az áttekintéshez részben azokat a szempontokat veszi figyelembe, amelyeket a tipológiában láttunk (az iménti két ábrán), részben további szempontokat alkalmaz (tesztelés, módszertan, a dokumentáció elérhetősége). Az alábbiakban bemutatok néhány ontológiai ajánlatot ezek közül.
Az első három konceptualizáció, az FBO (Frame-Based Ontology of Law), a FOLaw és az ODI a 90-es évek második felében született meg, és mindegyik különböző irányból közelíti meg a jog területét. R. W. van Kralingen (FBO) a Marvin Minsky által definiált „keretekből” indul ki. A korai mesterségesintelligencia-kutatás egyik fő kérdése az volt, hogy hogyan reprezentálható az emberi tudás, és ez a reprezentáció hogyan használható fel MI-alkalmazásoknál. A tudásaink jórészt sztereotipikus egységekből épülnek fel (lásd Marvin Minsky 1974-es tanulmányát): ilyen-és-ilyen rutinok mentén szerveződik például egy bevásárlás; vagy ha kutyát látunk, arra kell számítanunk, hogy esetleg megharap. Egy-egy fogalomról nem csak azt tudjuk, hogy milyen általánosabb kategória alá tartozik, hanem még sok minden mást is. A rigóról tudjuk, hogy madár; hogy gyakori faj, de kevésbé az, mint mondjuk a galamb; hogy kellemes, dallamos füttye van; hogy repül; stb. Akkor ismerünk egy fogalmat, ha többé-kevésbé ismerjük ezeket a fogalomhoz kapcsolódó elemeket. Ezeket hívja Minsky „kereteknek”. Egy-egy fogalomhoz egy-egy keret tartozik, amelynek vannak slotjai, azaz üres helyei, amelyeket ki tudunk tölteni. A keret a számítógép számára is értelmezhető tudásreprezentáció. Van Kralingen abból indul ki, hogy a jog és a jogról való tudás legfontosabb eleme a norma, és arra vállalkozik, hogy ontológiájában meghatározza a norma kereteit. Ez a keret tartalmaz kötelező (normatípus, alkalmazási feltétel, vonatkozás, jogi modalitás) és kiegészítő (azonosító, kibocsátó, hatály) slotokat. A norma mellett van Kralingen ontológiájában a jogi fogalmak és a jogintézmények kapnak helyet. Mindegyikhez tartozik egy-egy keretleírás. Az FBO eredetileg egy konceptuális, nem túl formalizált ontológia volt; később az ONTOLINGUA nevű leíró nyelvben specifikálták, és néhány alkalmazásban használták is.
Valente és Breuker 1996-os Functional Ontology of Law (FOLaw) rendszerét sokkal gyakorlatiasabb feladatok hívták életre. Egyfelől az alkotók szerették volna, ha a kidolgozott formalizmus jól használható lesz az oktatásban jogi esetek megvilágítására, másfelől ha informatikai támogatást nyújthat jogi problémák megoldásához. A mezzoontológiájukat is meghatározta ez a célkitűzés. A rendszer elkülöníti az egyes jogi tudástípusokat: normatív tudásokat, faktuális tudásokat, felelősségtudásokat, kreatív tudásokat és jogi metatudásokat. A különböző ágensek a működésük során ezeket a tudástípusokat használják. Az ON-LINE alkalmazásban ezt a – később a szerzők által kevésbé ontológiának, mintsem inkább episztemológiai keretnek tekintett – konceptualizációt jogi érvelések elemzésére használták.
Az FBO egyik fontos előzménye von Wright deontikus logikája; a normák keretleírásában is a svéd(-finn) filozófus elemzése köszön vissza. Ugyancsak von Wright az ihletője Hage és Verheij 1999-es ODI (Ontology of Law as a Dynamic Interconnected System of State of Affairs) névre hallgató ontológiájának. Ahogyan a hosszú elnevezés is sugallja, a rendszernek a szituációk (state of affairs) a központi kategóriája. A szituációk lehetséges világállapotok, amelyeket kijelentő mondatok tartalmának feleltethetünk meg. Tények a fennálló szituációk, nem-tények a (már) nem fennálló szituációk; ez utóbbiak lehetnek tartósak (például a francia forradalom kitörésének éve) vagy időlegesek, elkezdődhetnek és befejeződhetnek, stb. A szituációk mellett az események és cselekvések, a célok és szabályok az ontológia legfontosabb kategóriái. A jog szabályok mentén szituációkat rendel egymáshoz – a formalizmus pedig az egymáshoz rendelés kereteit adja meg. Az ontológia kiindulópontja a következő: „A jog szituációk rendszere. A jog dinamikus: a fennálló szituációk [tények] bizonyos események bekövetkeztével megváltozhatnak. A jog összekapcsolt [rendszer]: a tények között szabályokon alapuló (irányított) kapcsolatok állnak fenn.” (Jaap Hage – Bart Verheij: „The law as a dynamic interconnected system of states of affairs: a legal top ontology”, International Journal of Human-Computer Studies, 51 [1999], 1043–1077.)
Az ODI olyan eszköz, amely jogi szövegek és tudások reprezentálásához heurisztikus segítséget nyújt – legyen szó a szituációk, események és szabályok azonosításáról; szituációk szupervenienciájának leírásáról (lásd a madarak délre tartanak és a madarak költöznek); tények azonosításáról; események következményeit vezérlő szabályok azonosításáról; szabályok, elvek és célok elkülönítéséről; szabályok alkalmazhatóságának megállapításáról; vagy a szituációk fennállásának igazolásáról.
Az első mezzoszintű ontológiák főként holland jogi informatikai központokban jöttek létre. Akárcsak Hoekstra és Breuker LRI-Core-ja 2004-ben. Az LRI építését két elv vezérelte. Egyfelől az a meggyőződés, hogy a jogi fogalmak hétköznapi (common sense) fogalmakra épülnek; másfelől pedig hogy a mezzoontológia célja a jogi fogalmak mély strukturális reprezentálása. Az ontológia öt nagyobb fogalmi tartományból áll: fizikai világ, mentális világ, szerepek, absztrakciók és előfordulások (szituációk, történelem, téri-idői referenciák, események, okság, állapotok). Valójában az LRI felsőszintű ontológiához tartozó elemeket is felvesz, aminek az az oka, hogy a szerzők az akkor elérhető felsőszintű ontológiákat elsősorban természettudományos és formális tudományok dominálta konceptualizációnak tartották, amelyekből hiányzott a társas, kommunikatív világ leírása. Az LRI-Core formalizmusa az OWL leíró nyelv; egyik első alkalmazása a holland büntető törvénykönyv leírása volt. Az LRI egyik továbbfejlesztett változatának, az e-Courtnak az volt a célja, hogy a büntetőűgyes perek bírósági meghallgatásaink átiratait félig automatizált eszközökkel feldolgozzák, azaz kereshetővé és összekapcsolhatóvá tegyék.
Joost Breukernek, az LRI alkotójának volt egy korábbi munkája (lásd Den Haannal közösen írt 1991-es tanulmányukat: „Separating world and regulation knowledge: where is the logic?”, Proceedings of the third international conference on AI and Law, Oxford, ACM, továbbá Haan 1996-os doktori disszertációját: Automated legal reasoning, Amsterdami Egyetem), amelyhez ugyan nem kapcsolódott felsőbbszintű ontológiaépítés, mégis érdemes bemutatni, mert jól illusztrálja, mi mindenre használható a formalizmus. Az alkotók arra kaptak megbízást a holland közlekedésbiztonsági alaptól, hogy ellenőrizzék, vajon az új holland KRESZ (RVV-90) konzisztens és teljes-e. Továbbá megrendelést kaptak a szabályrendszer olyan formális újraírására, amelynek segítségével a későbbiekben oktatóprogramokat lehet készíteni. Breukerék a törvény alapján készítettek egy világmodellt, amely közlekedési szituációkat generált (például egy autó egyenrangú útkereszteződéshez ér, és jobbról érkezik egy kerékpáros). A szituációkat számítógép segítségével automatikusan generálták a közlekedési jogszabályban leírt lehetséges helyzetekből, és értékelést rendeltek hozzájuk a jogszabályból kivont előírások alapján. A program – a tervek szerint – egyfajta rendőri perspektívából értékelte (volna) a szituációkat. A projekt azonban befejezetlen maradt, részben informatikai nehézségek miatt, részben pedig a hiányzó felsőbb szintű kategóriák okán. Kis túlzással szólva ez a hiány vezetett el az LRI-hez. Hogyan működik ez a program? Például ha olyan közlekedési szituációt generálunk, amelyben egy villamos úttestbe süllyesztett villamospályán halad, azt az üzenetet kapjuk, hogy a villamos szabálytalanul közlekedik. Ugyanis a holland KRESZ (RVV-90) tételesen felsorolja, hogy milyen közlekedési eszközök haladhatnak a villamospályán (autóbuszok, taxik stb.) – s ezek közül kimaradt a villamos.
Hollandia mellett Olaszországban és Spanyolországban foglalkoznak jogiontológia-építéssel különböző akadémiai és üzleti kutatóközpontokban. Az egyik ilyen projekt a Jur-(Ital) Wordent és a CLO (Core Legal Ontology) volt. Aldo Gangemi és társai a Wordnet rendszere alapján a DOLCE felsőszintű ontológiát használva negyven fogalomból álló mezzoontológiát építettek. Többek között ezek a fogalmak szerepeltek az ontológiában: törvény, társadalmi norma, szabályozás, normatípusok (azon belül is konstitutív és regulatív norma), modális leírások (jogi pozíciók, azon belül is jogosultságok, kötelezettségek, felhatalmazottság), továbbá jogi szerepek, jogi ágensek, jogi információs artefaktumok. Ebben a – nem túl rendezett – felsorolásban két figyelemre méltó részlet akad. Az egyik az, hogy a szerzők a Wesley Newcomb Hohfeld által kidolgozott jogi pozíciókat is felveszik az ontológiai listába. (A korábban említett szerzők jogi, jogfilozófiai tekintetben H. L. A. Hartra, Hans Kelsenre és Jeremy Benthamra támaszkodtak.) Hohfeld jelentőségéről itt nincs lehetőségem részletesen írni (lásd Markovich Réka 2018-as doktori disszertációját: Deontic Logic and Formalizing Rights [ELTE] és syi cselekvéselméleti monográfiáját [syi.hu/cse, L’Harmattan–Könyvpont 2014]); röviden annyit mondanék, hogy a hohfeldi jogi pozíciók konceptualizálása valószínűleg az egyik legfontosabb eszköz, amit a következtetésre tervezett ontológia eszközként használni tud. A másik fontos részlet, hogy a korábban bemutatott ontológiákhoz képest a CLO sokkal átfogóbbnak tűnik: a normákon túl megjelennek benne események, ágenciák és a jogi normák érvényességét biztosító, dokumentumokban realizálódó jogi aktusok is.
Ezen átfogó jogi ontológiák kidolgozása mellett számos szűkebb jogi területet is formalizáltak az utóbbi években olyan ontológiai eszközök segítségével, amelyek túlléptek a szakontológiai törekvéseken. Főleg azokon a területeken, amelyeken elég erős piaci vagy állami szívóhatás volt jelen (európai ÁFA-rendeletek összehangolása, copyright, fogyasztóvédelmi törvények). Az új ontológiák jelentős része európai uniós támogatással jött létre, hiszen az uniós jogszabályok esetében a többnyelvűség okán komoly szükség lenne nyelvfüggetlen formális reprezentációra.
Az előző bekezdés utolsó félmondata viszonylag ártatlannak tűnik, de valójában egyáltalában nem magától értetődő, hogy a jog nyelvfüggetlen lenne. Bár a jogi rendszerek nagyon sok hasonlóságot mutatnak, hatalmasak a különbségek. A precedens- és a konstitucionális jogrendszerek egyszerű különbsége bonyolult helyzetet takar: a formálisan vagy informálisan konstitucionális rendszerekben is vannak példák a precedensszerű jogalkalmazásra. És természetesen számtalan olyan jogintézmény létezik, amely más jogi környezetben nem található meg, vagy másként tagozódva létezik. Például a családtámogatás intézménye a különböző jogrendszerekben más szinteken, más formákban valósulhat meg. Ezek rendszerfüggetlen leírása nem tűnik triviális feladatnak.
Casellas könyvének központi fejezete azonban mégiscsak annak a projektnek a bemutatása, amelyben a szerző maga is részt vett, és amely komoly újdonságot képviselt a korábbi ontológiákkal összevetve. (És talán módszertanilag is sokkal összeszedettebb volt.) A könyv korábbi fejezeteinek, amelyek részletesen bemutatják az eszközöket, nyelveket, ontológiákat és módszertanokat, és amelyeket igazságtalanul termékkatalógus-oldalaknak neveztem, többek között ez a rész ad értelmet. Így közelről szemügyre vehetjük, hogy az OJPK-t (Ontology of Professional Judicial Knowledge) milyen gondosan tervezték meg az alkotók, kiválasztva a lehetséges metodikák, újrahasznosítható felsőbb szintű ontológiák közül a céljaik számára legmegfelelőbbet. Az építkezés egy EU-s pályázat keretei között zajlott (SEKT project (IST-IP 2003-506826)), a projektnek nagyon sok résztvevője volt, nagyon sokféle felkészültséggel.
Az OPJK-projekt egyik legfontosabb sajátossága az előkészítésben rejlik. Jogi egyetemek hallgatóival és frissen munkába állt bírókkal készített mélyinterjúk után, valamint a kezdő bíróknak kínált telefonos gyorssegély-szolgálatra beérkező kérdések elemzésére támaszkodva (Mit csináljak, ha az igazságügyi orvosszakértő nem jött el a kitűzött meghallgatásra?) az alkotók megterveztek egy olyan FAQ-rendszert (Iuriservice) a bírói munka támogatására, amelyben természetes nyelvű kérdéseket lehetett feltenni a programnak. A releváns találatok szűkítését ontológiával segítették. Az ontológiaépítés tehát nagyon jól körülhatárolt célkitűzéshez kapcsolódott, a cél beállításához pedig empirikus megalapozást kerestek. A mélyinterjúk és a call centeres kérdések feldolgozásának az volt a célja, hogy az alkotók képesek legyenek azonosítani a valódi tudásigényeket és azokat a fogalmakat, amelyek ténylegesen leírják a bírói munkának a gyakorlati munkatapasztalattal megszerezhető területét.
Az alkotók a DOLCE és az LKIF-Core felső- és mezzoontológiáit használták az ontológiaépítésehez. Az ontológiai legfontosabb kategóriáit az alábbi ábra mutatja (a kötet 208. oldaláról).
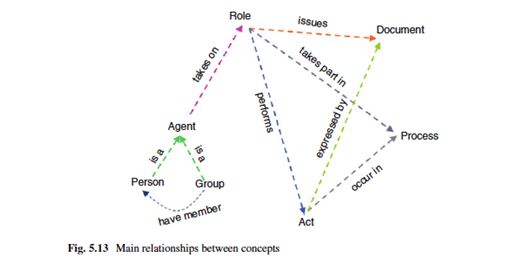
Casellas könyvének az a legfontosabb mondandója, hogy a jogi ontológiák építéséhez jogi, dogmatikai, jogalkalmazói ismeretekre és általában a joggyakorlat elmélyült ismeretére van szükségünk. Ez bizonyára így van, és érdemes keresni a lehetőségeket e szakértői tudások összekapcsolására (erre tettünk kísérletet idei tanulmányunkban, amely a jogi ontológiákban szereplő formális fogalmakat vizsgálja). Emellett azonban legalább ekkora szükség van a jól képzett filozófusok szaktudására – mert bár az ontológiaépítés viszonylag friss fejlemény, ám a filozófusok már nagyon régóta foglalkoznak ilyesmivel, és a felhalmozott ismereteiket nem tanácsos figyelmen kívül hagyni. Ha mégoly szűk területen szeretnénk is jogi ontológiát építeni, nagyon hamar bele fogunk ütközni olyan kérdésekbe, amelyek megválaszolása filozófiai tudást igényel. A családi viszonyok és rokonsági nevek taxonómiája viszonylag könnyű feladatnak tűnik (apja, unokatestvére stb.), de abban a jogi keretben, amelyben ténylegesen szükség van a rokonsági relációk kezelésére, jóval bonyolultabb kategoriális kapcsolatokkal találkozunk (különélő házastársa, nevelőszülője, béranya stb.). Hogy ne olyan kategóriarendszer szülessen, mint a Borges híres esszéjében idézett („idézett”) lista („az állatok lehetnek…”), jó észnél lenni. (Még ha a felsorolást a rossz ontológia állatorvosi lovaként szokás is emlegetni, a borgesi lista – a két nyilvánvaló csapda kivételével – tulajdonképpen nem is rossz. Erről majd máskor.)
Metafizikusok, szevasztok! Még több Ingardent a tudásreprezentációba! Formálontológusok, helló! Szükség van rátok, ahol mereológiailag rendezik a digitális jövőt!